Cloud data warehousing: quantitative asset management research meets academic expertise
Andre Fröhlich, Head of Research Technology at Quoniam, and Prof Dr Stephan König from Hannover University of Applied Sciences and Arts researched which prototypes of a cloud data warehousing architecture work in practice. We spoke with them about the advantages of a cloud architecture in investment research, the results of their research and the future relevance of this topic for Quoniam.

What does Quoniam’s investment research do?
Andre Fröhlich: The Research team develops our investment models and is responsible for our forecasts and the maintenance of our proprietary data warehouse. They focus on constantly improving our ability to make risk and return predictions. Additional research projects go beyond factor research, trying to capture technological and market developments, for example on ESG or machine learning, and turning them into added value.
Fast, efficient research has a direct impact on the strength of our investment strategies. In order for us to be able to process huge amounts of data quickly in the future, a certain infrastructure is necessary. This is why in 2020 we already started to gradually move our research to the cloud as well as switching to the future-proof programming language Python. We talked about this in a previous article.
What are the advantages of moving the central data storage of the investment research to the cloud?
Andre Fröhlich: It makes working with large amounts of data faster and more scalable. For example, if you want to analyse many different ESG data from different providers on tens of thousands of stocks over longer periods of time in a research project.
„The data warehouse in the cloud offers two major advantages: scalability – larger amounts of data can be analysed more quickly – and easier administration.”

Prof. Dr. Stephan König
Hannover University of Applied Sciences and Arts
Stephan König: Having the Data Warehouse in the cloud offers two big advantages: scalability – larger amounts of data can be evaluated faster – and easier administration. This means that you don’t have to do so much yourself. Many services are provided ready-made in the cloud without having to take care of the infrastructure, for example servers and their operating system. A good comparison is email providers like Gmail: here I can start right away and don’t have to worry about the technical setup.
Before we dive deeper into your research, what does the term cloud data warehousing actually mean?
Stephan König: A data warehouse is a central data store for large amounts of current and historical data integrated from many different source systems. This data store is used for various activities to enable data-driven decision support – for example in reporting or data analyses. This sometimes requires very long-running queries that aggregate large amounts of data.
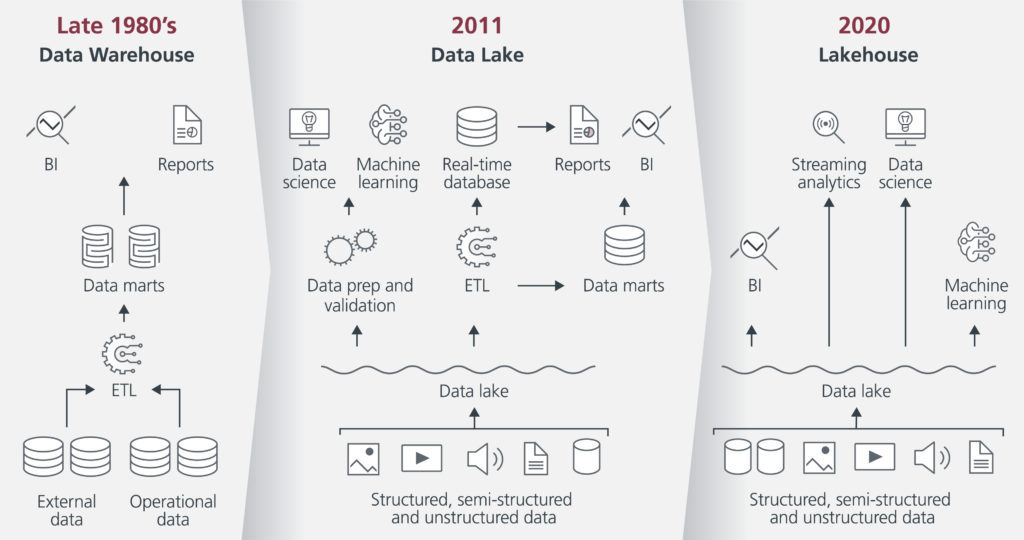
In the context of Big Data, a data lake is now often used to store structured and unstructured data. A data lake is characterised by being cost-efficient, cloud-based and capable of storing raw data. The combination of data lake and DWH is called a data lakehouse.
These are different stages in the development of the terms, as you can see in the chart below. For the sake of simplicity, we will refer to the original term data warehouse (DWH) in the following, but of course we mean the entire spectrum.
What was the main question of the project?
Andre Fröhlich: We wanted to find out whether the use of a cloud DWH is cost-effective for us at Quoniam and whether the positive effects of such a setup on performance justify the possibly higher costs that would be incurred. Other necessary prerequisites for an economically justifiable use in the company are good usability and the necessary degree of maturity of the technology, which was analysed as well.
How did you go about answering this question?
Stephan König: Using Quoniam as an example, we tested various prototypes for architectural approaches. For this, Quoniam provided real data sets and the corresponding environment with a modern cloud architecture. A small example to better illustrate the order of magnitude: In a typical analysis, 1 million data records are filtered and analysed from 1.5 billion data records within a few seconds.
First, we identified suitable cloud DWH scenarios based on business requirements and literature. We compared different setups of Microsoft Azure Synapse, Microsoft Azure SQL Database and Postgres DB. The main comparison criteria were the complexity/usability of the architecture, costs and performance.
Then a representative data analysis scenario was developed that was suitable for prototypical implementation and evaluation of the favoured architecture: the query of large factor data sets over longer time horizons. Special attention was paid to databases in the form of managed services, as these cause less administrative effort in later operation.
Andre Fröhlich: In addition, managed services usually offer the option of auto-scaling. This means that computing power can be automatically switched on and off as needed. This is particularly important for us. You only pay for the power you actually use (pay per use), which makes the whole thing more cost-efficient.
How did the results look like?
Stephan König: Azure SQL Serverless was not convincing in the tests. Even at maximum scaling, the runtimes were unacceptably long and led to high costs. Azure Synapse Dedicated, on the other hand, enabled runtimes and costs for the complex application scenario that are in the order of magnitude of the existing data lake architecture, even with small to medium scaling. In addition, the solution has almost unlimited scalability.
To complete the picture, Snowflake should also be examined. This cloud-based DWH solution offers further interesting advantages in addition to positive performance and cost aspects – for example, the possibility of connecting external data suppliers via a marketplace.
What does Quoniam do with these results? What are the next steps?
Andre Fröhlich: The final decision on whether to recommend the use of a Cloud DWH should be made after a test of Snowflake, which is already underway and being driven forward by our colleagues in the Technology department. Basically, however, we are quite sure that the topic will become interesting for us in the future.
“Thanks to the project, we at Quoniam were able to find out whether using a cloud DWH makes sense for us and how such a setup affects performance. A successful example of merging research and practice with profitable knowledge transfer!”

Andre Fröhlich
Head of Research Technology
And how does Hannover University of Applied Sciences and Arts benefit from the results?
Stephan König: The results are a great basis for further research projects in this area. Above all, they help to keep my teaching up-to-date and practice-oriented, which is a very valuable goal of our university. This will benefit my students – the next generation of data engineers. Therefore, I would like to take this opportunity to thank Quoniam once again for giving me the opportunity to carry out this research project together with them.
Will there also be cooperations in the future?
Andre Fröhlich: From Quoniam’s side, always a pleasure! It is great to bring together research and practice with such a competent partner and to enable a profitable transfer of knowledge. A concrete next idea would be to take another closer look at the topic of Snowflake in practice with student support.
Stephan König: I could not agree more. It was not without reason that this was the third project we worked on together. In previous years, there were already collaborations on the topic of Natural Language Processing and the evaluation of unstructured data from Twitter. Now I have spent my third practical research semester with Quoniam – and I hope that a fourth will follow.


